Unbounded PCollections, or unbounded collections, represent data in streaming pipelines. An unbounded collection contains data from a continuously updating data source such as Pub/Sub.
You cannot use only a key to group elements in an unbounded collection. There might be infinitely many elements for a given key in streaming data because the data source constantly adds new elements. You can use windows, watermarks, and triggers to aggregate elements in unbounded collections.
The concept of windows also applies to bounded PCollections that represent data in batch pipelines. For information on windowing in batch pipelines, see the Apache Beam documentation for Windowing with bounded PCollections.
If a Dataflow pipeline has a bounded data source, that is, a source
that does not contain continuously updating data, and the pipeline is switched to streaming
mode using the --streaming flag, when the bounded source is fully consumed,
the pipeline stops running.
Use streaming mode
To run a pipeline in streaming mode, set the --streaming flag in the
command line
when you run your pipeline. You can also set the streaming mode
programmatically
when you construct your pipeline.
Batch sources are not supported in streaming mode.
When you update your pipeline with a larger pool of workers, your streaming job might not upscale as expected. For streaming jobs that don't use Streaming Engine, you cannot scale beyond the original number of workers and Persistent Disk resources allocated at the start of your original job. When you update a Dataflow job and specify a larger number of workers in the new job, you can only specify a number of workers equal to the maximum number of workers that you specified for your original job.
Specify the maximum number of workers by using the following flags:
Java
--maxNumWorkers
Python
--max_num_workers
Go
--max_num_workers
Windows and windowing functions
Windowing functions divide unbounded collections into logical components, or windows. Windowing functions group unbounded collections by the timestamps of the individual elements. Each window contains a finite number of elements.
You set the following windows with the Apache Beam SDK:
- Tumbling windows (called fixed windows in Apache Beam)
- Hopping windows (called sliding windows in Apache Beam)
- Session windows
Tumbling windows
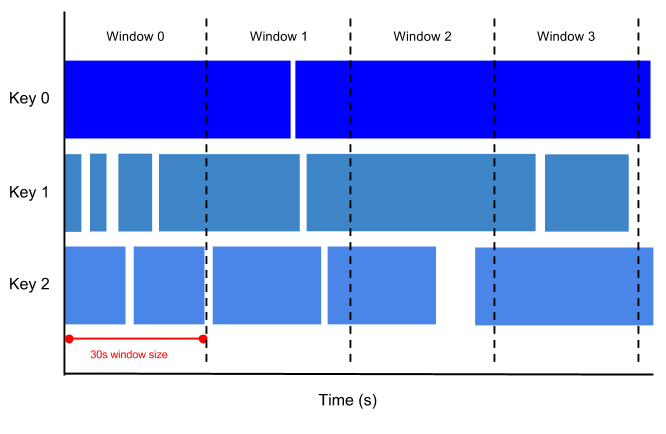
A tumbling window represents a consistent, disjoint time interval in the data stream.
For example, if you set to a thirty-second tumbling window, the elements with timestamp values [0:00:00-0:00:30) are in the first window. Elements with timestamp values [0:00:30-0:01:00) are in the second window.
The following image illustrates how elements are divided into thirty-second tumbling windows.
Hopping windows
A hopping window represents a consistent time interval in the data stream. Hopping windows can overlap, whereas tumbling windows are disjoint.
For example, a hopping window can start every thirty seconds and capture one minute of data. The frequency with which hopping windows begin is called the period. This example has a one-minute window and thirty-second period.
The following image illustrates how elements are divided into one-minute hopping windows with a thirty-second period.
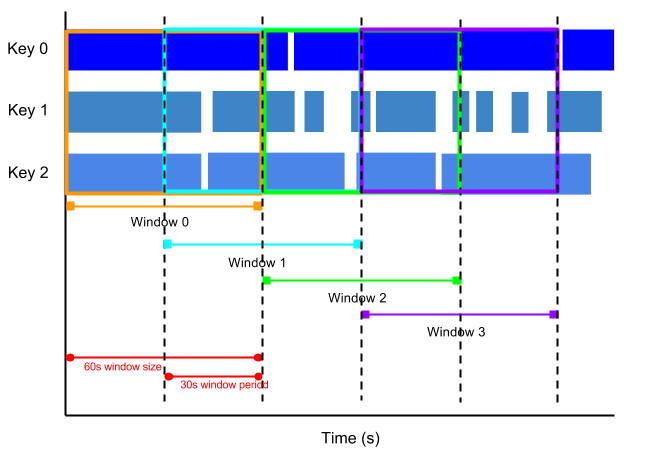
To take running averages of data, use hopping windows. You can use one-minute hopping windows with a thirty-second period to compute a one-minute running average every thirty seconds.
Session windows
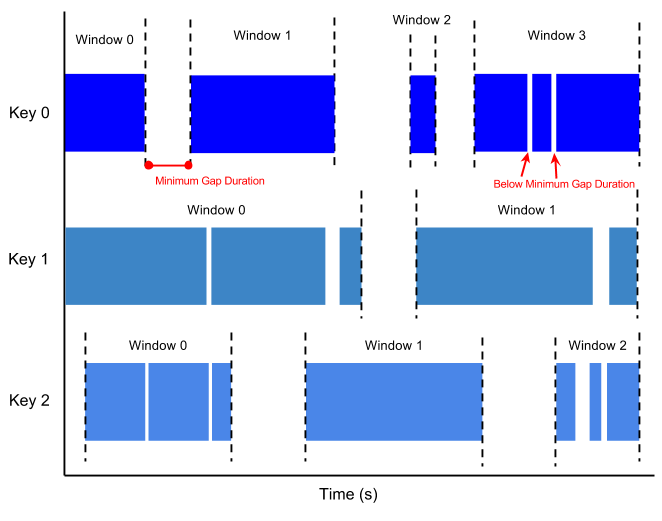
A session window contains elements within a gap duration of another element. The gap duration is an interval between new data in a data stream. If data arrives after the gap duration, the data is assigned to a new window.
For example, session windows can divide a data stream representing user mouse activity. This data stream might have long periods of idle time interspersed with many clicks. A session window can contain the data generated by the clicks.
Session windowing assigns different windows to each data key. Tumbling and hopping windows contain all elements in the specified time interval, regardless of data keys.
The following image visualizes how elements are divided into session windows.
Watermarks
A watermark is a threshold that indicates when Dataflow expects all of the data in a window to have arrived. If the watermark has progressed past the end of the window and new data arrives with a timestamp within the window, the data is considered late data. For more information, see Watermarks and late data in the Apache Beam documentation.
Dataflow tracks watermarks because of the following reasons:
- Data is not guaranteed to arrive in time order or at predictable intervals.
- Data events are not guaranteed to appear in pipelines in the same order that they were generated.
The data source determines the watermark. You can allow late data with the Apache Beam SDK.
Triggers
Triggers determine when to emit aggregated results as data arrives. By default, results are emitted when the watermark passes the end of the window.
You can use the Apache Beam SDK to create or modify triggers for each collection in a streaming pipeline.
The Apache Beam SDK can set triggers that operate on any combination of the following conditions:
- Event time, as indicated by the timestamp on each data element.
- Processing time, which is the time that the data element is processed at any given stage in the pipeline.
- The number of data elements in a collection.